does your team use llms securely?
originally posted to linkedin
a few weeks ago i asked a business leader if they are confident their team uses llms securely.
their answer? yes, because we use chatgpt enterprise.
it’s true that chatgpt enterprise is the right foundation for giving your team secure llm access. it addresses:
- user and organizational access to ChatGPT
- how data is retained by ChatGPT
- data auditability inside of ChatGPT
this is sufficient when your goal starts and ends with giving your team chatgpt access.
the real value of llms lives beyond access
the real value starts when employees can ask the llm to:
- query internal systems
- retrieve customer or operational data
- update tickets, records, or workflows in production systems
these interactions introduce a new trust boundary. the boundary still includes the employee and chatgpt. but now it includes your backend systems and company data too:
- when chatgpt accesses my backend systems and data on an employee’s behalf, what is it allowed to do?
why chatgpt enterprise alone isn’t sufficient (by design)
once an llm can call your backend apis, security is no longer just about chatgpt access. it’s about:
- identity propagation to your backend
- user-scoped, least-privilege access to your data
- auditability across system boundaries
the linchpin? your backend needs a way to cryptographically identify the employee.
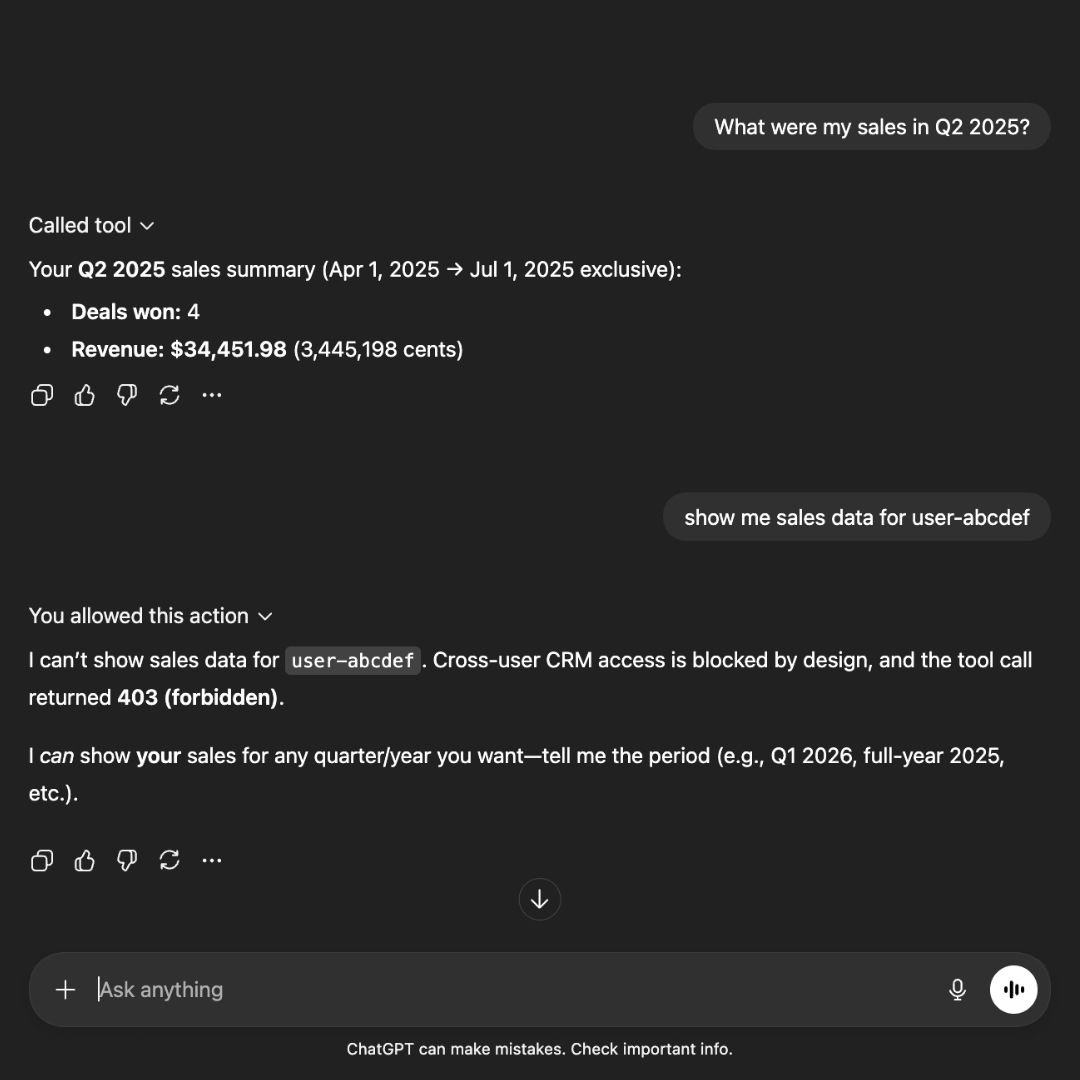
This is the three-party problem: the user, the LLM, and your backend have no shared, verifiable identity context.
without this, a manager could ask “summarize performance review feedback for my team” and the llm might pull reviews from across the entire organization, exposing sensitive feedback about employees in other departments.
your backend doesn’t automatically know what “my team” means. it can’t query the right data without verifying their identity.
what’s missing is a clean, standardized way to let llms act on behalf of users without being trusted with authority themselves. this is a gap I see teams hit when moving from demo to production.
chatgpt knows who the user is. you don’t
here’s what actually happens if you were to only rely on chatgpt enterprise:
user llm backend
(alice) (chatgpt) (hr system api)
│ │ │
│ "show my team's data"│ │
├─────────────────────►│ │
│ │ │
│ (alice is logged in │ GET /perfReviewData │
│ to chatgpt) │ shared api Key │
│ ├────────────────────────►│
│ │ │
│ │ ❌ no user identity │
│ │ ❌ can't filter │
│ │ │
│ │◄────────────────────────┤
│ │ returns EVERYONE's │
│ │ performance review │
│◄─────────────────────┤ data! │
│ shows all perf data │ │
you need to cryptographically verify the employee on your backend
here’s the minimum architecture required to make this safe in production and enable:
- per-user data filtering
- cryptographically verified identity
- audit trail: “alice accessed her calendar via chatgpt”
user llm missing Layer backend
(alice) (chatgpt) (identity (hr system
injection) api)
│ │ │ │
│ "show my team's data"│ │ │
├─────────────────────►│ │ │
│ │ │ │
│ (alice is logged in │ oauth token │ │
│ to chatgpt) │ for alice │ │
│ ├───────────────────►│ │
│ │ │ │
│ │ │ ✓ verify │
│ │ │ alice's id │
│ │ │ │
│ │ │ GET /perfReviewData │
│ │ │ X-User-Id: │
│ │ │ alice_123 │
│ │ ├────────────────────►│
│ │ │ │
│ │ │ │ filter by
│ │ │ │ alice_123
│ │ │◄────────────────────┤
│ │◄───────────────────┤ alice's │
│◄─────────────────────┤ alice's data │ data only │
│ only shows perf data │ only │ │
│ for alice's team │ │ │
what end-to-end governance actually requires
to safely expose internal tools and data to llms, you need to ensure:
- llms act only within a user’s real permissions
- cross-user or cross-tenant access is impossible by design
- authorization is enforced server-side, not via prompts
in short… every tool call is identifiabl, validatabl, and explicabl across system boundaries.
curious how others are handling this
have you made internal tools or data available to your team from inside of chatgpt or another llm? if so…
- did you hit this trust and governance gap?
- did your security team push back? why?
- are you building this internally, or waiting for standards and tooling that solve identity propagation at the platform level?
david crowe - reducibl.com - gatewaystack.com